









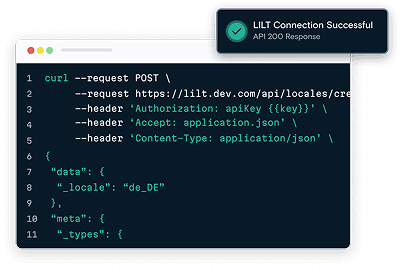
SFT programs we run
 Prompt–response authoring and targeted rewrites aligned to your instruction regime.
Prompt–response authoring and targeted rewrites aligned to your instruction regime.- Preference and judgment data to complement SFT with alignment-ready signals.
- Domain grounding + RAG validation to verify answers follow the provided context and constraints.