









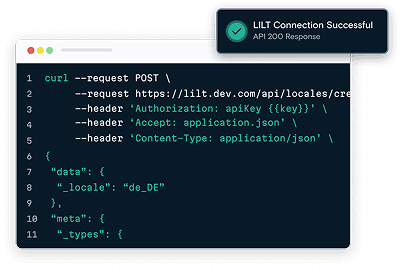
What you can do with LILT
 Preference ranking and pairwise comparisons across languages and cultural contexts.
Preference ranking and pairwise comparisons across languages and cultural contexts.- Rubric-driven evaluations for instruction-following, helpfulness, and policy adherence.
- Longitudinal monitoring to keep preference signals stable as models and policies evolve.