AI Data Services
May 18, 2026
|
4 min read
The Hidden AI Coding Gap: Why Non-English Development Lags Behind
AI coding tools score high on English benchmarks but fail non-English developers. LILT's research reveals systematic gaps in Arabic character shaping, Korean grammar, and locale handling, showing leading models like GPT-5.5, Gemini 3.1 Pro, and Claude Opus 4.7 drop sharply when tasks switch from English to native languages.
LILT Team

The dominant AI coding benchmarks assume developers work in English. They don’t. Millions of programmers operate daily in Arabic, Korean, German, Mandarin, and dozens of other languages, facing coding challenges English-first models were never trained to handle.
At LILT, we’ve been systematically mapping these blind spots, revealing a persistent gap between benchmark performance and real-world utility for non-English developers.
Why English-Only Benchmarks Miss the Multilingual AI Coding Gap
State-of-the-art models now achieve high scores on leading coding benchmarks like HumanEval and MBPP. However, these benchmarks were originally built in English, and even recent multilingual extensions such as mHumanEval and MAPS primarily rely on translating the surface text of the problems. They rarely incorporate the deeper cultural, linguistic, and technical contexts that make coding tasks feel truly native in other languages.
The result: models that appear capable but consistently fail on the kind of problems that non-English programmers encounter every day.
We’ve built a taxonomy of ten multilingual programming pain points, covering Arabic character shaping and right-to-left rendering, legacy encoding detection, locale-aware sorting, Korean grammatical morphology, and culture-specific calendar systems, among others. These aren’t obscure edge cases. They’re the daily reality of developers working outside the English-language programming world.
A few of the most illustrative examples are below. To obtain the complete list, contact us.
How Leading AI Models Fail on Arabic and Korean Coding Tasks
To demonstrate the problem concretely, we built coding tasks drawn directly from native non-English developer workflows. Each targets a specific failure mode and each breaks current leading models in instructive ways.
Arabic Coding Failures: Encoding, Character Shaping, and Language Fallback
The task: Given a CSV of cloud service costs, generate a bar chart breaking down cost per service. The file uses a legacy Arabic encoding rather than Unicode, and the chart labels must render correctly in Arabic.

Why AI Models Fail at Arabic Encoding Detection
The model decoded the file using the wrong character set, producing garbled text, and failed to recognize that the output was nonsensical.

Why Arabic Character Shaping Breaks AI-Generated Code.
Arabic letters change form depending on their position in a word. Without applying character shaping, rendered text appears as disconnected, reversed glyphs, a step models regularly omit.
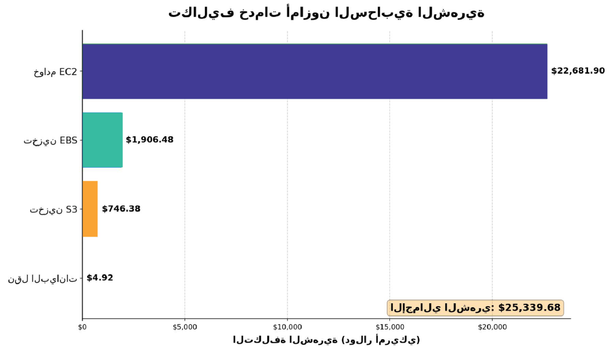
Why Models Default to English Despite Arabic Prompts.
Though prompted in Arabic, models frequently produced the chart labels in English instead.
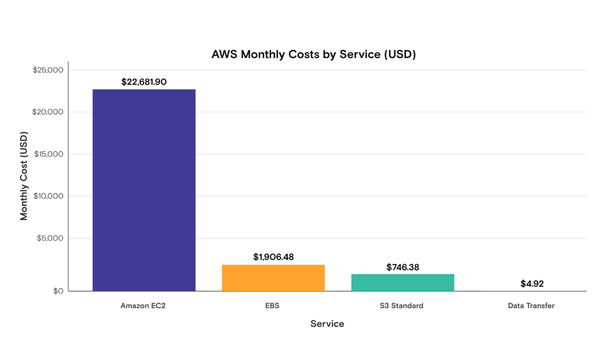
Performance Comparison: English vs. Arabic Bar Chart Generation
| Model | Success Rate (English) | Success Rate (Arabic) |
|---|---|---|
GPT-5.5 | 2 / 5 | 0 / 5 |
Gemini 3.1 Pro | 4 / 5 | 1 / 5 |
Claude Opus 4.7 | 5 / 5 | 1 / 5 |
This is a canonical example of a task that is routine for Arabic-speaking developers but invisible to English-trained benchmarks. To measure this disparity, we compared performance against a functionally identical English plotting task. Every model tested loses ground when the task switches from English to Arabic, and even the strongest score (Claude Opus 4.7 at 5/5) collapses to 1/5 in the native condition. Note that these results were compared to the
Korean Coding Failures: Grammatical Particles in Generated Text
The task: Generate a customer-facing payment notification from a payment log and user database, a common backend task. In English, this is simple string formatting (100% pass rate).

Success rate in English: 5/5 for all three models (GPT 5.5, Gemini 3.1 Pro, Claude Opus 4.7)

Now, let’s execute the same task in Korean by switching the language of input data and prompt, so the two tasks in different languages are comparable in terms of task structure:


Performance Comparison: English vs. Korean Notification Generation
| Model | Success Rate (English) | Success Rate (Korean) |
|---|---|---|
GPT-5.5 | 5 / 5 | 1 / 5 |
Gemini 3.1 Pro | 5 / 5 | 0 / 5 |
Claude Opus 4.7 | 5 / 5 | 0 / 5 |
How Korean Particles (을/를, 로/으로) Trip Up LLMs
In Korean, grammatical particles (such as 를/을 and 로/으로) change form based on whether the preceding noun ends in a consonant or vowel. This is implicit knowledge for any Korean speaker but requires custom Unicode-aware logic to implement correctly in code.
All three models score a perfect 5/5 in English. In Korean, GPT-5.5 manages 1/5; Gemini 3.1 Pro and Claude Opus 4.7 both score 0/5.

Models could solve the structural problem but had no awareness of the linguistic constraint that Korean-speaking users take for granted. This gap between “English fluency” and “functional localization” is exactly what existing benchmarks miss.
What the Multilingual AI Coding Gap Means for Developer Tools
These examples are representative of the everyday friction that non-English developers experience when using AI coding tools. The underlying issues of encoding detection, script rendering, grammatical morphology, and locale-aware sorting are well understood in their respective language communities. This isn’t rare for non-English developers, it’s everyday, and English-first models often miss it.
This isn’t about benchmarks alone, it’s about the product. AI tools positioned as universal coding assistants are currently delivering a meaningfully worse experience to a significant share of the world’s developers.
The path forward requires multilingual benchmarks built from the ground up with native language expertise, not translated from English, and training data that reflects real, language-specific developer challenges.
Partner With LILT on Multilingual AI Evaluation
LILT specializes in identifying the multilingual failure modes that English-first evaluation misses, and building the data needed to fix them. LILT leverages its native-speaker networks, linguistic expertise, and benchmarking infrastructure to help AI teams understand where their models fall short for non-English users.
If you're building AI coding tools and want to evaluate or improve multilingual performance, get in touch with our team. We'd love to talk.
Contact Us
Ready to build a benchmark that measures what your multilingual AI actually does?
Book a MeetingShare this post
Share this post